
Il y a environ deux semaines, deux grands modèles d’IA ont été abandonnés presque simultanément : OpenAI a publié GPT-5.5 – un modèle phare avec des scores de référence qui réinitialisent le classement, tandis que DeepSeek, le laboratoire d’IA basé à Hangzhou, en Chine, a publié son propre nouveau modèle V4.
Le contraste n’était pas celui auquel on s’attendait. Le lancement d’OpenAI a été un tour de victoire. DeepSeek est venu avec un aveu discret enfoui dans son rapport technique : la V4, selon ses propres estimations, est en retard sur GPT-5.4 et Gemini 3.1 d’environ trois à six mois.
Dans une industrie où chaque lancement de modèle est accompagné d’un graphique montrant que vous battez tout le monde dans quelque chose, c’était presque du jamais vu.
Alors pourquoi DeepSeek, un laboratoire qui a terrifié les entreprises occidentales d’IA avec sa rentabilité, admettrait-il ouvertement qu’il ne gagne pas la course aux capacités brutes ?
Les spécifications qui ont fait la une des journaux – téléchargement gratuit, contexte d’un million de jetons, prix absurdement bas – ne sont pas ce qui rend la V4 stratégiquement significative. La véritable histoire est ce qui se passe lorsque vous essayez d’utiliser une fenêtre contextuelle contenant un million de jetons.
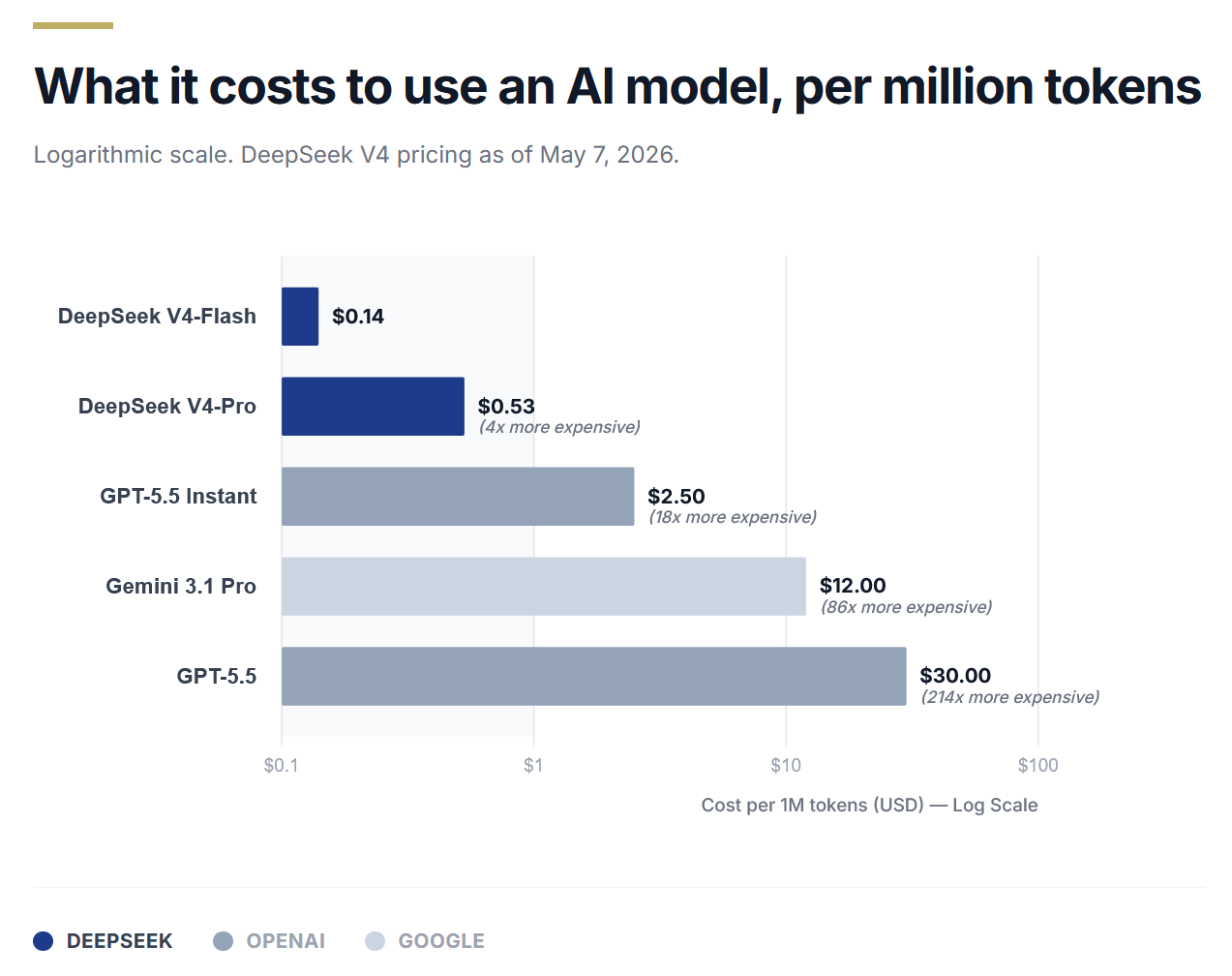
Dans un modèle standard, les besoins en mémoire explosent à mesure que le contexte s’allonge. La V4 résout ce problème avec une astuce brutalement efficace : les compresser. Considérez-le comme la différence entre conserver chaque image d’un film et conserver un résumé de chaque scène. En conséquence, la charge de mémoire a été réduite de 90 pour cent.
Un autre élément d’ingénierie qui mérite d’être compris est que l’équipe DeepSeek a troqué les performances brutes des références contre la stabilité de la formation – un choix que les laboratoires obsédés par les références ne font généralement pas.
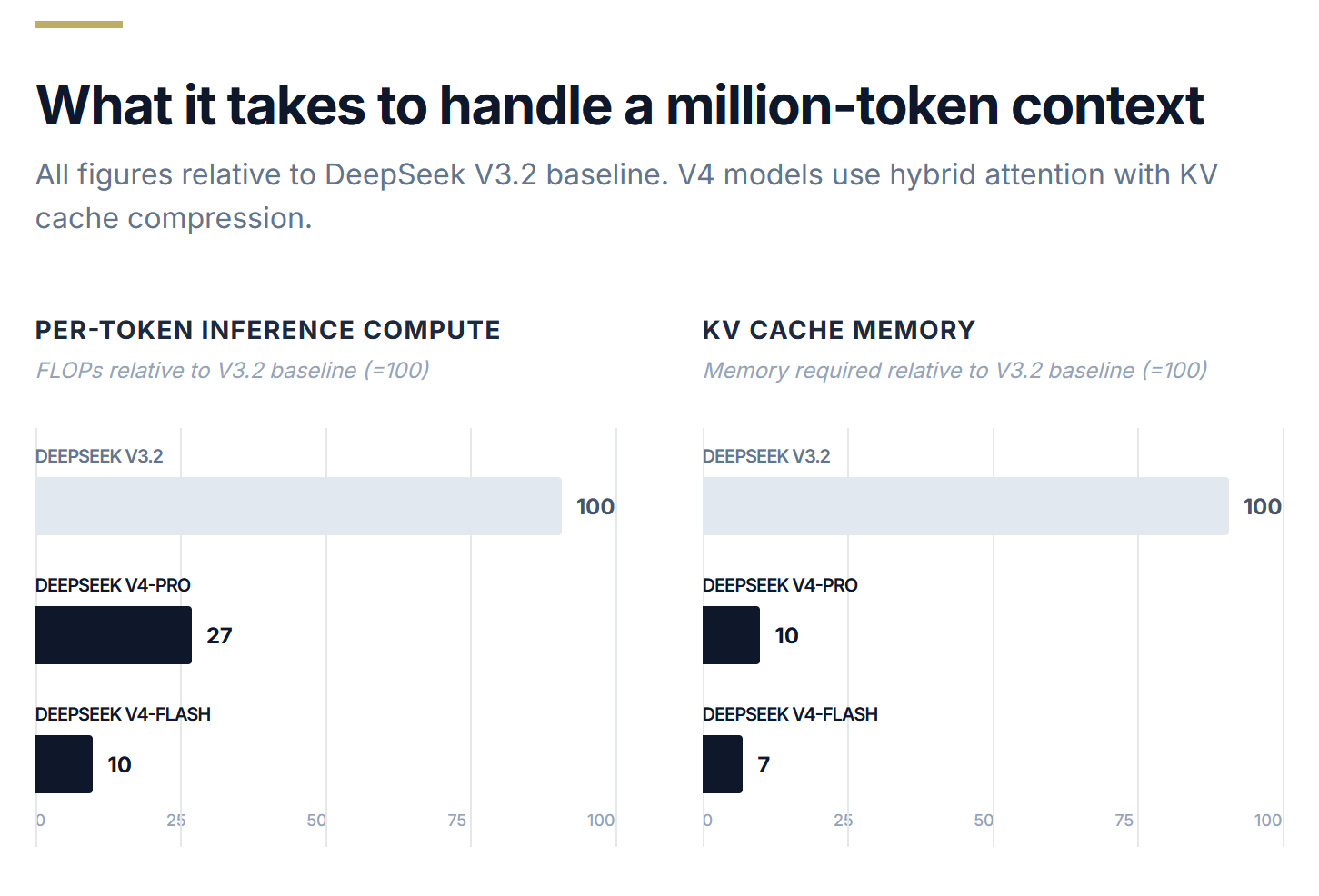
Pris ensemble, ces choix techniques vont dans une seule direction. DeepSeek n’essaie pas de créer le modèle le plus puissant possible. Il essaie de construire le plus pratique. Celui qui fonctionne sur le matériel que les gens possèdent réellement, à des coûts qui ne nécessitent pas l’approbation d’une réunion budgétaire de l’entreprise. Cela s’avère être un problème d’ingénierie beaucoup plus difficile et beaucoup plus intéressant.
La V4 était censée être expédiée des mois plus tôt. Ce n’est pas le cas. La raison n’était pas une mystérieuse instabilité de la formation ou un changement d’architecture de dernière minute. C’était des chips.
DeepSeek a décidé de migrer la V4 de l’écosystème CUDA de Nvidia vers la plateforme de calcul Ascend de Huawei.
Pendant des années, la règle tacite de l’IA de pointe a été de fonctionner sur Nvidia – non pas parce que le silicium de Nvidia est intrinsèquement supérieur dans toutes les dimensions, mais parce que l’écosystème logiciel CUDA est si profondément intégré que le changement est économiquement irrationnel. Développeurs formés sur CUDA. Des frameworks ont été construits pour CUDA. Les bibliothèques d’opérateurs ont supposé CUDA. Changer de puces signifiait reconstruire l’intégralité de votre chaîne d’outils.
L’équipe DeepSeek a dû réécrire à partir de zéro plus de 200 opérateurs principaux. Les premières sessions de formation sur le matériel Ascend se sont écrasées à plusieurs reprises. Huawei a envoyé des ingénieurs sur place. La collaboration a finalement produit un pipeline fonctionnel, mais il a fallu 15 mois de ce que plusieurs sources ont décrit comme une migration pénible et pénible.
Un ingénieur a calculé sur les réseaux sociaux que l’exécution de V4-Flash sur un super-nœud Ascend 950, à concurrence équivalente, coûte 40 à 60 % de moins en matériel qu’une configuration Nvidia comparable. « Pas parce que je veux soutenir les puces nationales », ont-ils écrit. « Parce que les mathématiques fonctionnent. » V4 et Ascend ont démontré qu’un chemin non-CUDA est viable.
Il y a ici un fil plus subtil qui n’a reçu presque aucune couverture en anglais. L’architecture d’attention hybride de la V4 est une spécification implicite pour la prochaine génération de puces IA.
La technologie de compression de la mémoire déplace le goulot d’étranglement de la mémoire vers le calcul. Si un modèle comme le V4 devient l’architecture dominante, la conception optimale de la puce change. Vous n’avez plus besoin d’une énorme mémoire à large bande passante. Le logiciel écrit, en fait, les spécifications matérielles.
C’est l’inverse de la façon dont Nvidia a bâti sa domination. CUDA a créé un écosystème logiciel si profondément enraciné que les clients du matériel ne pouvaient pas le quitter. DeepSeek tente l’image miroir : créer une architecture de modèle si convaincante et si efficace que toute puce espérant exécuter de futures charges de travail d’IA devra suivre son plan. Il s’agit d’un matériel définissant le logiciel, et cela placerait une société chinoise d’IA – et non un géant des puces de la Silicon Valley – dans le fauteuil de l’architecte.
En concédant ouvertement la couronne de capacités brutes, DeepSeek fait quelque chose qu’aucun laboratoire d’IA occidental n’a été prêt à faire : recadrer ce que signifie « gagner ».